一、引言
在大模型训练与人工智能应用全面普及的今天,人工智能基础设施也逐渐走进大众视野。“我们的模型是怎么被训练出来的?”“大量算力究竟跑在什么地方?”这些原本只属于技术团队的讨论,如今正成为企业数字化转型中的核心议题。随着算力需求以指数级增长,如何构建、验证并交付一套稳定、高效、可扩展的科学计算/人工智能基础设施,正成为所有追求智能化竞争力的组织无法回避的问题。本篇将以此为切入点,探讨新一代科学计算/人工智能基础设施的交付标准与实施要点。
二、观念重构:这不是服务器,是“算力生命体”
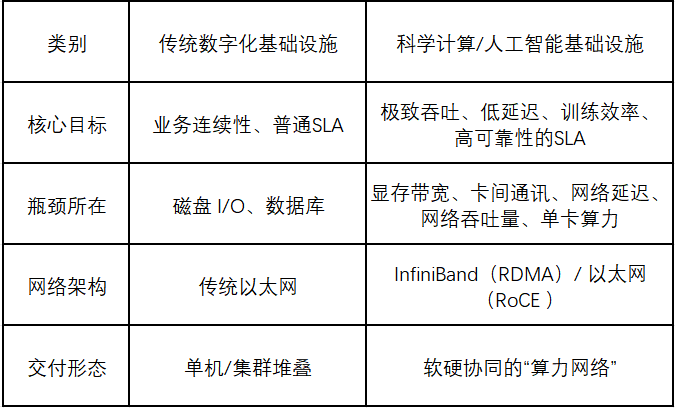
传统 IT基础设施对比科学计算/人工智能基础设施
在智算时代,仅仅把服务器堆在一起并配置好传统网络是无法完全跑通的,至少在应用层面会遇到各种各样的问题,最主要体现在兼容性、性能、可靠性等决定集群可用性的问题。
IBM在人工智能基础设施报告内指出:传统 IT 的核心是“稳定与兼容”,而人工智能基础设施的使命是“性能与效率”。
我们可以通过一个表格来直观对比两者的差异:
科学计算/人工智能基础设施的设计不再是单一服务器或集群的堆叠,而是一个“算力网络”体系:
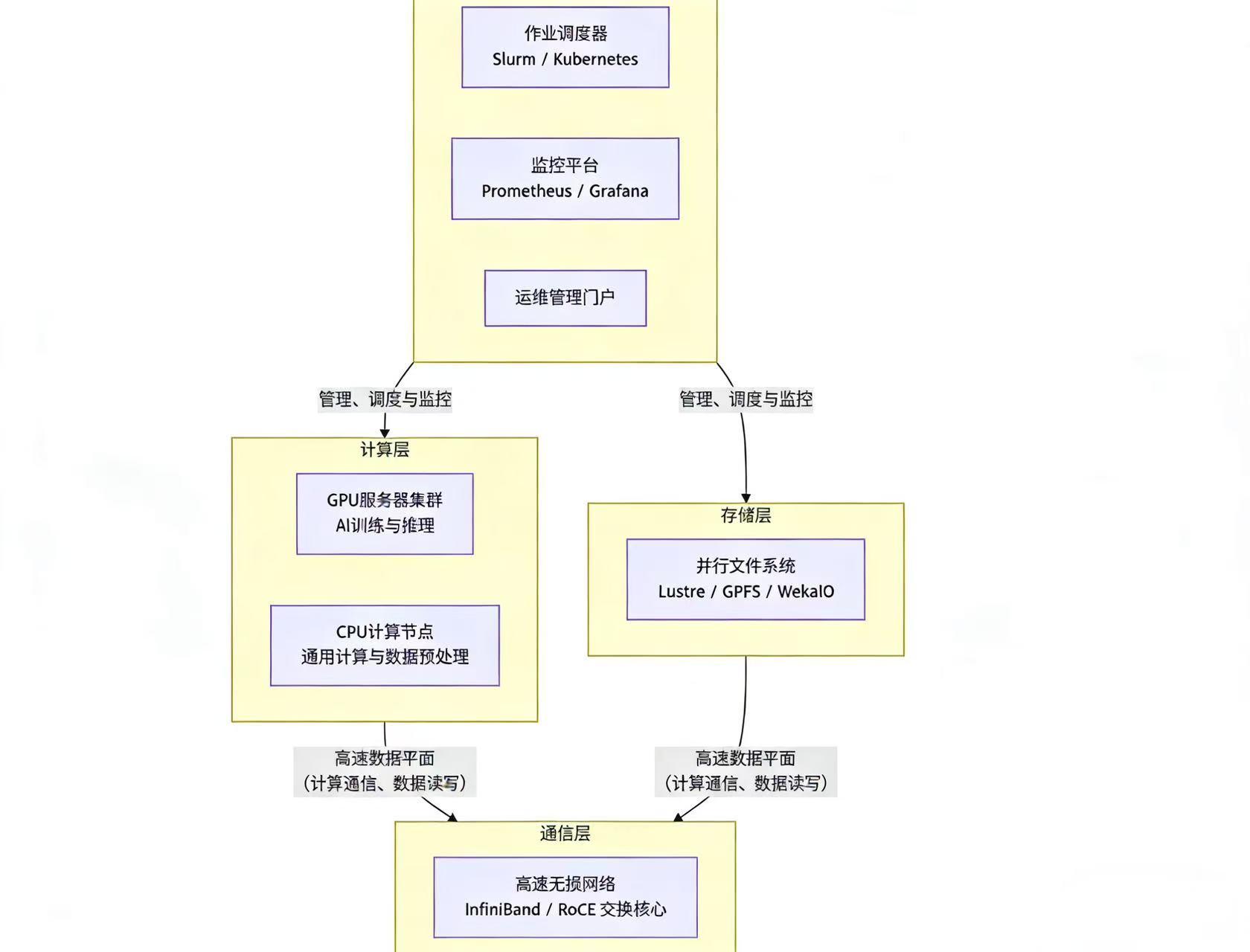
科学计算/人工智能基础设施真正的价值,在于让算力像电力一样可调用、像网络一样可扩展、像系统一样可自愈。
三、科学计算/人工智能基础设施交付标准:从硬件一致到性能验收
在智算中心和人工智能集群的落地过程中,“交付”是质量与可信度的分水岭。只有经过严苛测试与标准化验证的系统,才能在大模型训练中保持稳定高效,来看看我们在交付前是怎么做的。
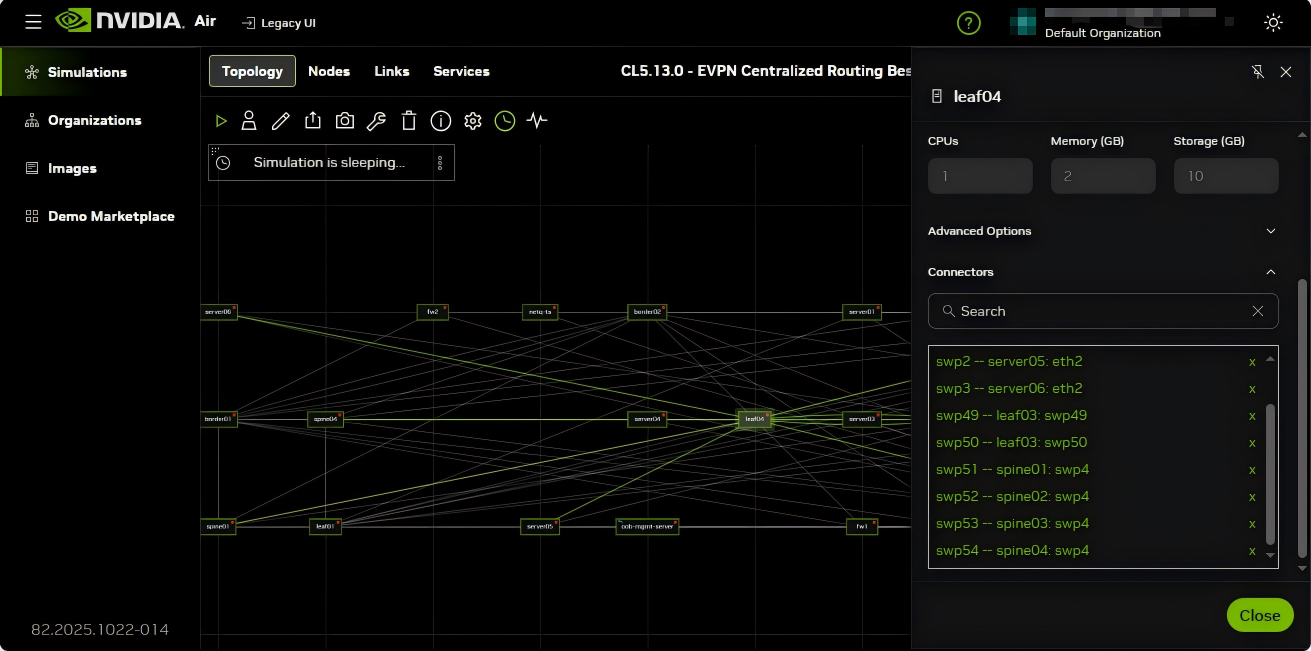
使用NVIDIA Air创建集群数字孪生
数据中心基础设施日益复杂,需要高效的解决方案来简化网络运营。NVIDIA Air 通过创建真实数据中心基础设施部署的相同副本,提升云规模效率。NVIDIA Air 允许用户使用完整的软件功能对数据中心部署进行建模,从而创建数字孪生。通过仿真、验证以及自动化变更和更新,转变并加速人工智能落地时间。
基础设施仿真:基于 Linux 的开放、云原生架构,可通过浏览器 GUI 或 CLI 表示基于NVIDIA的以太网交换机与通用服务器
网络即服务:适用于 Cumulus Linux、SONiC 和 NetQ 等网络软件堆栈的、基于裸金属的仿真
主机支持:x86 服务器仿真(包含操作系统、应用等)
预构建网络模板:配备完备的叶脊网络架构,运行多种 NOS 以进行网络功能测试,减少了在实际项目中遇到的网络配置等其他突发情况而造成的问题,缩短了项目整体的构建与交付时间。
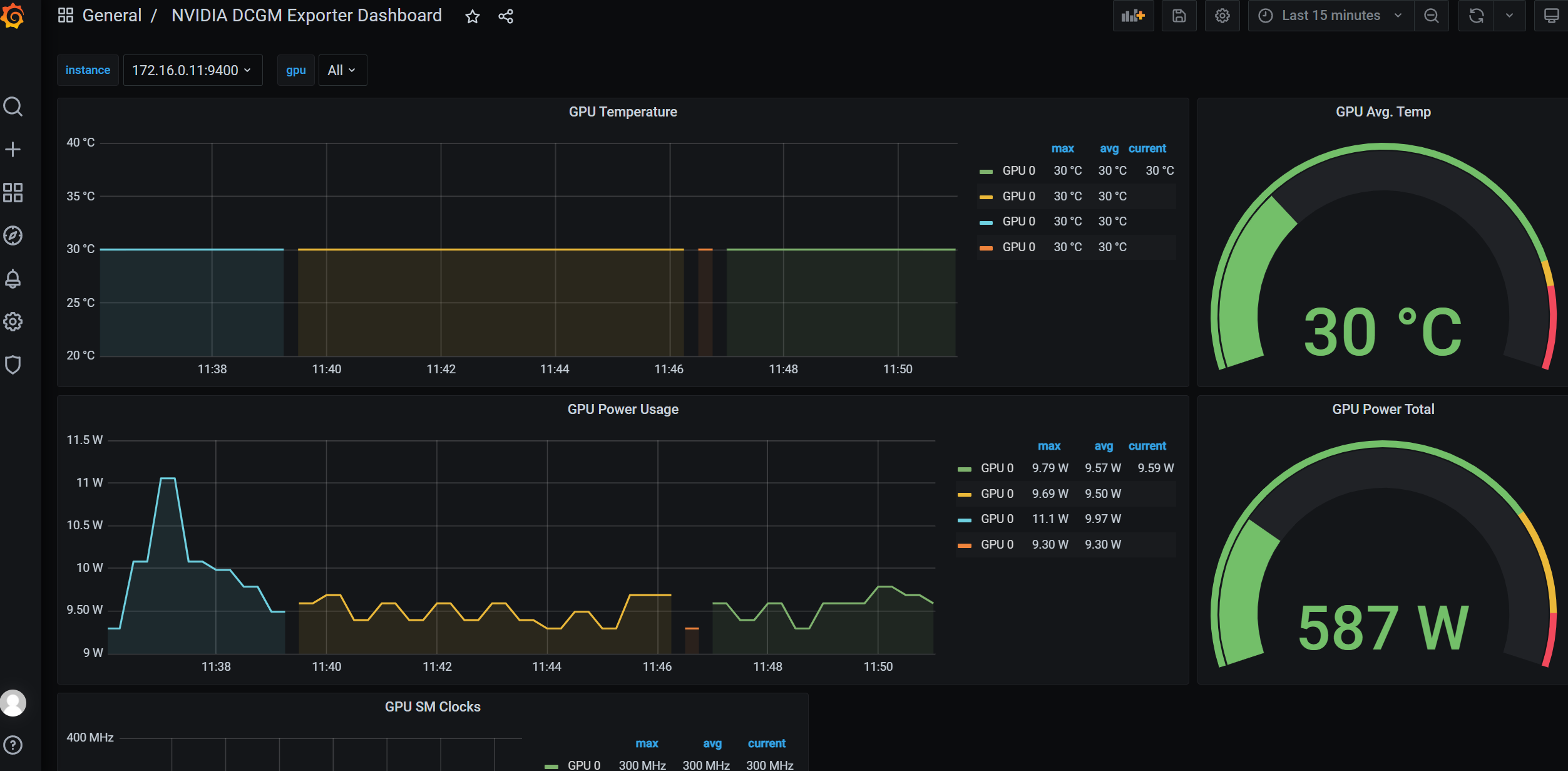
2.1 硬件一致性与健康性
CPU:在集群中,CPU不仅要关注单个核心的温度与频率,更需关注所有节点整体使用率的均衡性,是否存在部分节点因软件锁或硬件瓶颈(如PCIe通道故障)而长期降频,影响性能导致利用率低等问题。 验收需要关注型号、物理核心数、逻辑核心数、主频。

GPU:这是智算集群的绝对核心。诊断需覆盖每张GPU卡的核心温度、显存温度、功耗、计算与显存使用率。尤其在高强度模型训练中,显存的健康(如ECC纠错计数)至关重要,频繁的纠错可能预示显存颗粒的物理老化。更关键的是,需要检测是否存在慢节点——即节点内某张GPU故障或ECC错误而导致训练中断集群性能测试的问题,也就拖慢了交付的进度。验收时关注型号、数量、显存、GPU驱动版本、CUDA驱动版本。

图片来自NVIDIA官网
存储:对于NVMe SSD,需监控其读写带宽、IOPS(每秒读写操作次数)以及延迟。更重要的是,通过SMART信息预测寿命,避免在训练中途因硬盘故障而导致的任务中断。
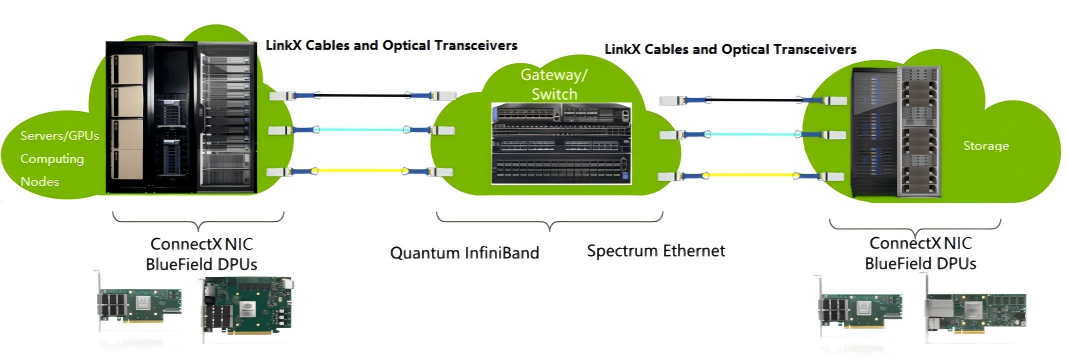
InfiniBand(RDMA)/以太网(RoCE)网络:需要在交付前进行长时间的性能压力测试,以检测交换机端口状态、光模块温度与收发光功率。光功率衰减是常见故障点。其次,需监控链路带宽利用率、误码率、丢包率与通信延迟。通过运行all-to-all测试。计算网卡(InfiniBand/以太网)的型号、固件版本,同时网卡的版本与交换机的固件版本对应。
2.2 性能与稳定性验证
通过系统化压力测试,确保每个节点在高负载下仍能保持线性性能:
CPU/内存压力测试:Prime95或stress-ng持续运行72小时无错误;
GPU稳定性测试:NVIDIA DCGM与GPU Burn监控显存、温度与稳定度;
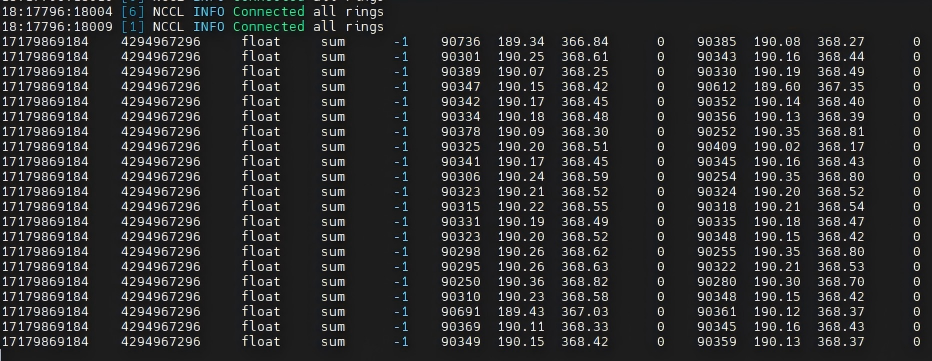
存储I/O性能测试:验证4K随机读写及顺序带宽达到预测标准;
RDMA集合通信网络性能测试:
在做大模型训练、科学计算应用时,很多服务器不是各自干各自的活,而是要一起协同工作。为了让它们能又快又稳地交换数据,我们一般会用到 RDMA 这种比普通网络更快、更低延迟的通信方式。
但问题来了,这些服务器之间要经常做“集合通信”,比如大家一起广播一份参数、一起做 All-Reduce 聚合梯度。如果网络不稳定、不够快、延迟忽高忽低,就会拖慢整个训练进度,甚至让任务直接失败。
所以在集群交付前整体测试一遍网络性能是必须要做的事情,否则在交付后,很可能因为无法正常进行通信,单点故障也可能导致无法正常训练、推理,从而导致集群无法交付。
2.3 通信网络健康与拓扑验证
人工智能集群性能瓶颈多源于通信层。交付阶段需要检查交换机端口与光模块状态;绘制“网络心电图”,提前排查慢链路;使用ibdiagnet与perftest工具进行链路完整性验证。
唯有稳定的通信底座,才能让算力真正释放,否则按照现有算力资源设计,任何单节点的故障都可能导致集群的可用性降低,从而导致业务停滞。
四、人工智能未来的方向:智能化、绿色化、可观测化
随着人工智能应用的规模化扩展,科学计算/人工智能基础设施的交付标准也在不断演进:
1. 智能且高效的运维算力基础设施
通过GPU Telemetry、DCGM与IB监控实现全栈可观测,支持预测性维护与自动修复。
2. 弹性算力池化
随着GPU虚拟化与云原生调度技术成熟,人工智能集群正向算力池化架构演进,支持多任务、多租户、优先级的灵活调度,让算力可以按需使用。借助 GPU 资源切分与弹性伸缩技术,平台能将 GPU 利用率从传统的 10%~20% 提升至 50%~60%,部分场景可达 70%~80%,为算力高效利用提供了技术保障。
3. 绿色数据中心
液冷系统与动态功耗管理技术让人工智能集群能效显著提升,PUE可降至1.2以下,打造低碳智算中心。
4. 标准化交付体系(重点)
从硬件验收、性能基线到文档化验证,人工智能集群交付正迈向体系化与可追溯标准,为企业提供可靠、透明的交付保障。
以下是我们在实施过超万卡GPU总结的验收标准项:

五、人工智能基础设施的建设与总结
现在的人工智能基础设施,已经远远不是“把服务器拼在一起”那么简单了。随着模型越来越大、业务越来越复杂,仅仅拥有算力并不能保证系统真正跑得快、跑得稳。企业需要一套标准化、智能化、可验证的建设与交付体系——从机房规划、硬件部署、网络架构,到软件环境、模型训练,再到性能验证、稳定性测试,每一步都要做到可复现、可检查、可追踪。只有这样,企业才能真正实现从“堆算力”到“用好算力”的转变,让人工智能系统不仅能运行,更能持续稳定地输出价值,加速智能应用落地,最终完成从构建算力基础到释放智能生产力的跨越。

扫描二维码获取更多资料
